Als ich mit dem PIVOT-Konstrukt arbeitete und performante Ergebnisse haben wollte, muss ich erst verstehen, wie es intern arbeitet. Das beschrieb ich im Artikel "SQL-Server-2005: schnelles Pivot?". Diese Serie soll meine Erfahrungen weitergeben und bei Verstehen der Zusammenhänge helfen. Mit ein paar Kniffen kann man dann die Ausführung erheblich beschleunigen. Der Quellcode zu diesem letzten Artikel steht übrigens hier.
Performance von "gejointen" Daten
Wenn die Basistabelle des PIVOTs aus einer Derived-Table besteht, die mittels Join die Daten aus mehreren Tabellen sammelt, dann hängt es von relativ vielen Faktoren ab, ob das PIVOT schnell ist. Das gleiche gilt natürlich auch, wenn der PIVOT auf eine View oder eine Inline-Table-Valued-Function durchgeführt wird.
Man kann es aber auf den Nenner bringen: Kann der Optimizer das PIVOT so begrenzen, dass die Gruppierung allein auf den Werten einer Tabelle basiert, die mittels Clustered-Index gelesen werden können, dann ist es schnell. In den anderen Fällen muss man mit mehr oder weniger starken Performanceeinbußen rechnen.
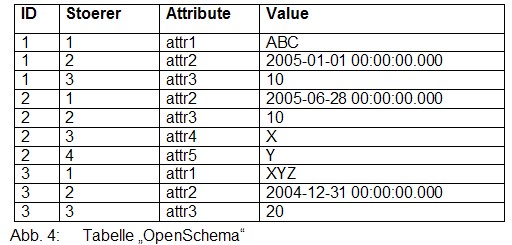
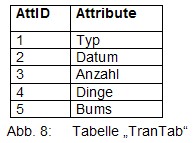
Als Beispiel möchte ich einen relativ gängigen Sonderfall darstellen: Das Beispiel des ersten Artikels wird so erweitert, dass die Spaltenüberschriften in einer Translation-Table TranTab stehen:
In der Tabelle OpenSchema steht dann der Verweis auf den Namen des Attributes:

Um das gewünschte Ergebnis zu bekommen, muss man PIVOT auf eine Derived-Table ausführen:
SELECT ID, "Typ", "Datum", "Anzahl", "Dings", "Bums"
FROM (SELECT os.ID, tt.Attribute, os."Value"
FROM OpenSchema as os
JOIN TransTab as tt
ON os.AttId=tt.AttId) as dt
PIVOT
(
Max("Value")
FOR Attribute IN ("Typ", "Datum", "Anzahl", "Dings", "Bums")
) AS pvt
ORDER BY ID
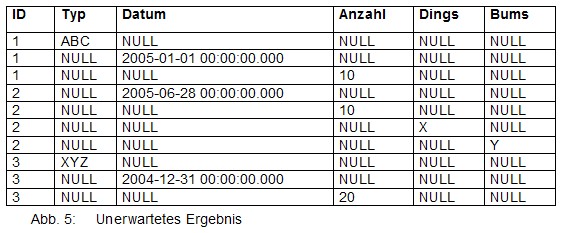
Die Performance verschlechtert sich dadurch dramatisch. Im Vergleich zum reinen Lesen der Daten fast um Faktor 4. Das liegt am ungünstigen Zugriffsplan:

Wenn man einen PIVOT ohne den Join durchführt, dann erhält man die gewohnte, gute Performance:
SELECT ID, "1" as "Typ", "2" as "Datum", "3" as "Anzahl", "4" as "Dings", "5" as "Bums"
FROM (SELECT os.ID, os.AttId as Attribute, os."Value"
FROM OpenSchema as os ) as dt
PIVOT
(
Max("Value")
FOR Attribute IN ("1", "2", "3", "4", "5")
) AS pvt
ORDER BY ID
Leider muss man dazu die Spaltenamen "hart" codieren. Das ist aber genau das, was man vermeiden wollte als man die Translation-Table einführte. Um auch mit flexiblen Spaltennamen zu einer guten Performance zu kommen, muss man im Batch zunächst die Spalten ermitteln, das PIVOT-Statement dann dynamisch zusammensetzen und ausführen:
DECLARE @sqlcmd nvarchar(1000),
@selectList nvarchar(1000),
@pivotList nvarchar(1000);
SELECT
– zunächst die Spalten aus der SELECT-Liste ermitteln
@selectList = STUFF(
(SELECT N', '+QUOTENAME(AttId)+N' AS '
+QUOTENAME(Attribute) AS [text()]
FROM TransTab
ORDER BY AttId
FOR XML PATH('')), 1, 1, N''),
– dann die Liste der Spalten ermitteln
@pivotList = STUFF(
(SELECT N', '+QUOTENAME(AttId) AS [text()]
FROM TransTab
Order BY AttId
FOR XML PATH('')), 1, 1, N'');
SET @sqlcmd = N'SELECT ID, '+@selectList +N'
FROM (SELECT os.ID, os.AttId as Attribute, os."Value"
FROM OpenSchema as os) as O
PIVOT (Max("Value") FOR Attribute IN ('+@pivotList+N')) as P
ORDER BY Id;'
EXEC sp_executesql @sqlcmd;
Das ausgeführte Statement sieht dann so aus:
SELECT ID, [1] AS [Typ], [2] AS [DATUM], [3] AS [Anzahl], [4] AS [Dings], [5] AS [Bums]
FROM (SELECT os.ID, os.AttId as Attribute, os."Value"
FROM OpenSchema as os) as O
PIVOT (Max("Value") FOR Attribute IN ( [1], [2], [3], [4], [5])) as P
ORDER BY Id;
Die Gesamtperformance dieses Beispiels ist wieder sehr gut.
Insgesamt ergeben sich mit Pivot eine Menge neuer Möglichkeiten. Wenn dabei die Performance wichtig ist, dann muss man sich jedoch genau überlegen, wie man das Statement auch wirklich schnell ausführen kann.
Diese Reihe schrieb ich letzten Oktober als Reaktion auf den Aufruf im SQL-PASS-Newsletter. Möglicherweise erscheint der Artikel noch dort. Ich veröffentliche ihn jetzt aber lieber mal bevor er mit dem bald erscheinenden SQL-Server-2008 möglicherweise veraltet… 😉