




Als ich mit dem PIVOT-Konstrukt arbeitete und performante Ergebnisse haben wollte, muss ich erst verstehen, wie es intern arbeitet. Mit ein paar Kniffen kann man dann die Ausführung erheblich beschleunigen. Diese Serien soll meine Erfahrungen weitergeben und bei Verstehen der Zusammenhänge helfen. Der Quellcode zu diesem Artikel steht übrigens hier.
- Artikel 1: Wie wird Pivot abgearbeitet?
- Artikel 2: Störer beim PIVOT eliminieren
- Artikel 3: Pivot-Performance
- Artikel 4: Pivot-Performance mit Joins
Wie wird PIVOT ausgeführt?
Angenommen die Tabelle „OpenSchema“ besteht aus drei Spalten: einer ID, einem Attributbezeichner und einer Wert-Spalte. Das sähe etwa so aus:
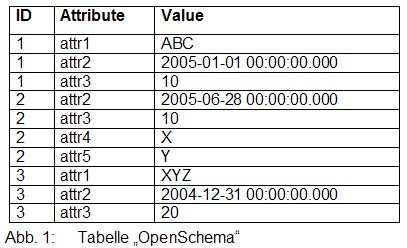
Um die Ergebnisse dieser "Kennziffer-Wert-Tabelle" in "relationaler" Form zu präsentieren, müssen die Ergebnisse pivotiert werden:

Vor dem SQL-Server-2005 war dazu ein recht kompliziert aussehendes Konstrukt notwendig: Man musste pro Ergebnis eine Aggregatfunktion auswerten, dass intern mittels CASE nur die gewünschten Ergebnisse auswertet:
SELECT ID,
MAX(CASE WHEN "Attribute" = 'attr1' THEN "VALUE" END) as "Typ",
MAX(CASE WHEN "Attribute" = 'attr2' THEN "VALUE" END) as "Datum",
MAX(CASE WHEN "Attribute" = 'attr3' THEN "VALUE" END) as "Anzahl",
MAX(CASE WHEN "Attribute" = 'attr4' THEN "VALUE" END) as "Dings",
MAX(CASE WHEN "Attribute" = 'attr5' THEN "VALUE" END) as "Bums"
FROM OpenSchema
GROUP by ID
ORDER BY ID
In dieser Form stellten es Rozenshtein, Abranovich und Birger schon 1992 im "SQL Server Forum 12/1992" vor. Damals gab es nur das CASE-Konstrukt noch nicht, deswegen verwendeten sie verschiedene Tricks, um ein CASE auf mathematische Weise zu erreichen. Der Vorteil bei dieser alten Schreibweise ist, dass man die Gruppierung explizit angeben kann.
Pivotieren mit Pivot
Im SQL-Server-2005 führte Microsoft bekanntlich das PIVOT-Konstrukt ein, um das Ganze zu vereinfachen. Im PIVOT-Statement wird die Gruppierung hingegen implizit durchgeführt: Es wird nach allen Spalten der Tabelle gruppiert, die nicht in den Klammern des PIVOT genannt werden. Unten werden "Value" und "Attribute" genannt, also wird nach allen verbleibenden gruppiert: hier nur "ID".
SELECT ID,
attr1 as Typ,
attr2 as Datum,
attr3 as Anzahl,
attr4 as Dings,
attr5 as Bums
FROM OpenSchema
PIVOT (
MAX("Value")
FOR Attribute IN ("attr1", "attr2", "attr3", "attr4", "attr5")
) AS pvt
ORDER BY ID
Das PIVOT-Konstrukt ist genauso implementiert, wie es bereits oben beschrieben wurde. Das schließe ich daraus, dass in beiden Fällen der gleiche Zugriffsplan verwendet wird:

Natürlich passiert es öfters, dass der Optimizer einen semantisch äquivalenten Zugriffsplan verwendet, wenn er effizienter ist. Das ist hier jedoch unwahrscheinlich.
Die "ältere" Form hilft mir zu verstehen, wann ein PIVOT schnell ausgeführt werden kann und wann er einfach langsam sein muss. Sie hat zudem den Vorteil, dass man pro Spalte entscheiden kann, welche Aggregatfunktion verwendet werden soll. Beim neuen PIVOT wird für alle die gleiche genutzt.